
Since the launch of ChatGPT over two years ago, we have observed that our clients are increasingly drawn to the promise of AI. They also recognize that the large language models (LLMs), trained on public data sets, may not effectively solve their domain-specific problems. Consequently, it would be essential to integrate domain knowledge into these AI systems to furnish them with a structured understanding of the organization. Recently, my colleague Lulit Tesfaye described three key strategies to enable such knowledge intelligence (KI) in the organization via expert knowledge capture, business context embedding and knowledge extraction using semantic layer assets and Retrieval Augmented Generation (RAG). Incorporating such a knowledge intelligence layer into enterprise architecture is not just a theoretical concept anymore but a critical necessity in the age of AI. It is a practical enhancement that transforms the way in which organizations can inject knowledge into their AI systems to allow better interpretation of data, effective reasoning and informed decision making.
When designing and implementing KI layers at client organizations, our goal is always to recommend an architecture that aligns closely with their existing enterprise architecture, providing a minimally disruptive starting point.
In this article, I will describe the common architectural patterns we have utilized over the last decade to design and implement some of the KI strategies such as automated knowledge capture, semantic layers and RAG across a diverse set of organizations. I will describe the key components of a KI layer, outlining their relationship with organizational data sources and applications through a high-level conceptual framework. In subsequent blogs, I will delve deeper into each of the 3 main strategies that details how KI integrates institutional knowledge, business context and human expertise to deliver on the promise of AI for the enterprise.
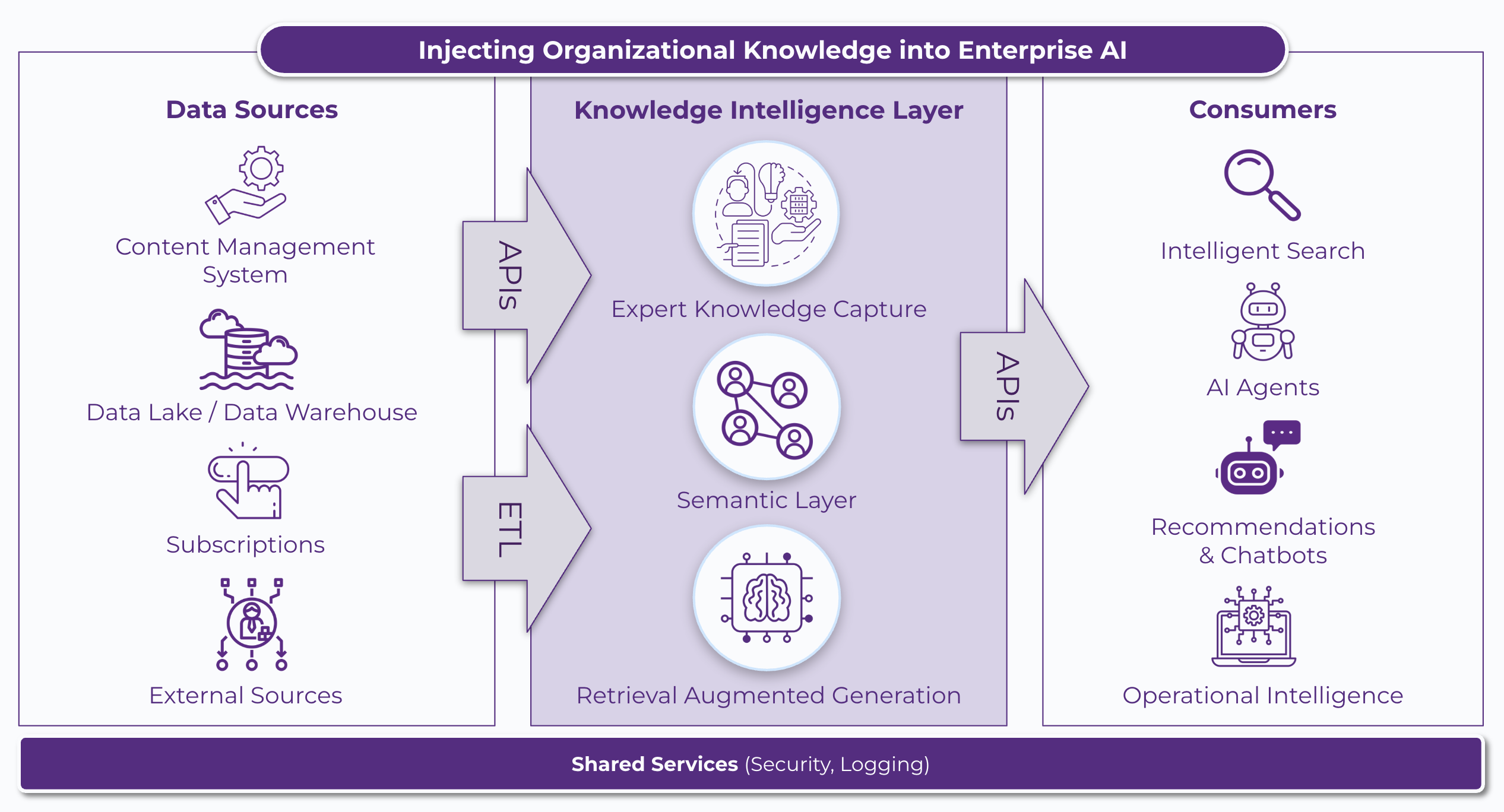
Enterprise AI Architecture: Knowledge Intelligence
Semantic Layer
A semantic layer provides standardized meaning and business context to aggregated data assets in an organization, allowing AI models to understand and process information more accurately and generate more relevant insights. Specifically, it can offer a more intuitive and connected representation of organizational data entities without having to physically move the data and it does so through use of metadata, business glossaries, taxonomies, ontologies and knowledge graphs.
When implementing a semantic layer, we often encounter this common misconception that a semantic layer is a single product such as a graph database or a data catalog. While we have been developing the individual components of a semantic layer for almost a decade, we have only been integrating them all into a semantic layer in the last couple of years. You can learn more about the typical semantic layer architectures that we have implemented for our clients here. For implementing specific components of the semantic layer before they can all be integrated into a logical abstraction layer over enterprise data, we work with most top vendors in the space and leverage our proprietary vendor evaluation matrix to identify the appropriate tool for our client whether it is a taxonomy ontology management platform (TOMS), a graph database or a data catalog. You can read this article to learn more about our high level considerations when choosing any knowledge management platform including semantic layer tools.
Expert Knowledge Capture
This KI component programmatically encodes both implicit and explicit domain expert knowledge into a structured repository of information, allowing AI systems to incorporate an organization’s most valuable assets, its tacit knowledge and human expertise into its decision making process. While tacit knowledge is difficult to articulate, record and disseminate, using modern AI tools, it can be easily mined from recorded interactions (such as meeting transcripts, chat history) with domain experts. Explicit knowledge, although documented, is often not easily discoverable. State-of-the-art LLM models and taxonomies, however, make tagging this knowledge with meaningful metadata quite straightforward. In other words, in the age of AI while content capture may be a breeze, transforming the captured content into knowledge requires some thought. You can learn more about the best practices we often share with our clients for effective knowledge base management here. In particular, we have written extensively about improving the quality of knowledge bases using metadata and the big role taxonomy plays in it. With a taxonomy in place, it all comes down to teaching a machine learning (ML) model the domain-specific language that is used to describe the content so that it can accurately auto-classify it. See this article to learn more about our auto-tagging approach.
Another aspect of expert knowledge capture is to engage domain experts in annotating datasets with contextual information or providing them with an embedded feedback loop to review AI outputs and provide corrections and enhancements. While annotation and feedback capabilities can be included in a vendor platform such as a data science workbench in a data management platform or taxonomy concept approval workflow in a taxonomy management system, we have implemented custom workflows to capture this domain knowledge for our clients as well. For example, you can read more about our human-in-the-loop taxonomy development process here or SME validation of taxonomy tag application process here.
Retrieval Augmented Generation
A Retrieval Augmented Generation (RAG) framework allows LLMs to access up-to-date organizational knowledge bases instead of relying solely on the LLM’s pre-trained knowledge to provide more accurate and contextually relevant outputs. An enterprise RAG application may even require reasoning based on specific relationships between knowledge fragments to collect information related to answering who/what/when/how/where questions as opposed to relying only on semantic similarity with complete knowledge base items. Thus we typically leverage two or more types of information retrieval systems when solving KI use cases through RAG for our customers.
In its most basic form, a RAG application can be developed with an LLM, an embedding model and a vector database. You can read more about how we implemented this architecture to power semantic search in a multinational development bank here. In reality, however, RAG implementations rely on additional information retrieval systems in the enterprise such as search engines or data warehouses as well as semantic layer assets such as knowledge graphs. In addition, RAG applications require elaborate data orchestration between the available knowledge bases and the LLM; popular frameworks such as LangChain and LlamaIndex can greatly simplify this orchestration by providing abstractions for common RAG steps such as indexing, retrieval, and workflows. Finally, to take any POC implementation of a RAG application to production, we need to leverage some of the data integrations and shared services such as monitoring, security described below.
Data Integration
Just like any data integration, aggregation and transformation layer, a KI layer depends on various tools to extract, connect, transform and unify both structured and unstructured data sources. These tools include ELT (Extract, Load and Transform) and ETL (Extract, Transform and Load) tools, like Apache Airflow, API management platforms, like MuleSoft, and data virtualization platforms, like Tibco Data Virtualization. Typically, these integration and transformation patterns are well-established within organizations; hence, we often recommend that our clients reuse proven design patterns wherever possible. Additionally, we advise our clients to leverage established data cleansing techniques before sending the data to the KI layer for further enrichment and standardization.
KI Applications
While chatbots remain the most common application of KI, we have leveraged KI to power intelligent search, recommendation engines, agentic AI workflows and business intelligence applications for our clients. In our experience, KI applications range from fully custom applications such as AI agents to configurable Software-as-a-Service (SaaS) platforms such as AI search engines.
Shared Services
Services including data security management, user and system access management, logging, monitoring and other centralized IT functions within an organization will need to be integrated with the KI layer in accordance with established organizational protocols.
Case Study
While we have been implementing individual KI components at client organizations over the past decade, only recently we have begun to implement and integrate multiple KI components to enable organizations to extract maximum value from their AI efforts. For example, over the last two years we established a data center of excellence at a multinational bank to enable effective non-financial risk management by implementing and integrating two distinct KI components: semantic layer and expert knowledge capture and transfer. Using a semantic layer, we injected business context into their structured datasets by enriching it using a standardized categorization structure, contextualizing it using a domain ontology and connecting it via a knowledge graph. As a result, when instantiated and deployed to production, the graph became an authoritative source of truth and provided a solid foundation for advanced analytics and AI capabilities to improve the efficiency and accuracy of the end-to-end risk management process. We also implemented the expert knowledge capture component of KI by programmatically encoding domain knowledge and business context into the taxonomies and ontologies we developed for this initiative. For example, we created a new risk taxonomy by mining free text risk descriptions using a ML pipeline but significantly shortened the overall development time by embedding human feedback in the pipeline. Specifically, we provided domain experts with embedded tools and processes to review model outputs and provide corrections and additional annotations that were in turn leveraged to refine the ML models and create the finalized taxonomy in an iterative fashion. In the end both KI components enabled the firm to establish a robust foundation for enhanced risk management; it powered consumer-grade AI capabilities running on the semantic layer that streamlined access to critical insights through intelligent search, linked data view and query, thereby improving regulatory reporting, and fostering a more data-driven risk management culture at the firm.
Closing
While there are a number of approaches to designing and implementing the core KI components described above, there are best practices to ensure the quality and scalability of the solution. The upcoming blogs in this series zoom into each of these components, enumerate the approaches for implementing each component, discuss how to achieve KI from a technical perspective, and detail how each component would support the development of Enterprise AI with real-life case studies. As with any technical implementation, we recommend grounding any KI implementation effort in a business case, starting small and iterating, beginning with a few source systems to lay a solid foundation for an enterprise KI layer. Once the initial KI layer has been established, it is easier to expand the KI ecosystem while enabling foundational AI models to generate meaningful content, make intelligent predictions, discover hidden insights, and drive valuable business outcomes.
Looking for technical advisory on how to get your KI layer off the ground? Contact us to get started.